







Introduction

Picture published by La Gazzetta di Mantova
Natural disasters do occur (the above picture shows the top of a tower falling down in Mantova, a city 5 Km away from Spazio IT offices, during a small quake which occurred in May 2012 in an area that was supposed to be absolutely free from any seismic risk).
Blaise Pascal, a French seventeenth century philosopher and scientist, once wrote “Man is but a reed, the most feeble thing in nature [..]. The entire universe need not arm itself to crush him. A vapour, a drop of water, suffices to kill him.”
In IT terms a data centre (even a cloud data centre – nowadays a very fashionable expression) may stop being available even without the occurrence of a natural disaster. A general connectivity problem, a fire, some problem in the power grid, may cause the data centre not to function properly.
Continuing with Pascal’s quote: “But if the universe were to crush him, man would still be more noble than that which killed him, because he knows that he dies and the advantage which the universe has over him; the universe knows nothing of this.”
Again in IT terms, we have a brain, we have the possibility to design architectures, system configurations that are very resilient and can even survive natural disasters.
The key: Redundancy
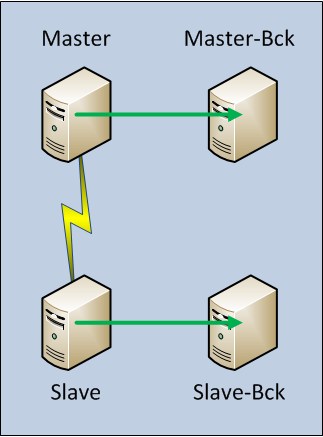
The key is very simple: Redundancy: instead of having one single system running in one data centre, two different systems (one the copy of the other) running in two different data centres have to be used.
These two systems are: the master system (used in normal conditions) and the slave system (used only when the master in not available).
Each system is composed of a server machine and a back-up machine (a machine or a FTP/NFS area where the back-up is performed). The server machine and the back-up machine are local to each other (they are on the same local network in the same data centre).
Logical needs and physical constraints
From a logical point of view:
- the master and the slave should be one the clone of the other (or as similar as possible)
- the farher away the master and the slave are the safer, the more resilient and robust the configuration is
but
- the farter away the master and the slave are the more difficult is to guarantee they can be identical at an affordable cost.
If the connection between the master system and the slave system is very fast (e.g. in fiber) it is possible to perform almost a continuous real time update of the two systems. In case the connection is not so fast, and depending on the amount of data that need to be exchanged, only few updates a day are possible .
Break up scenarios and inversion of roles
- The slave system breaks up – the master system is still working. If and when the slave system re-starts to work the auto update mechanism will refresh its contents without any problem.
- The master system breaks up – the slave system is still working (though it contains data consistent with the last update) and can be immediately used. If and when the master system re-starts to work the auto update mechanism must be either stopped or an inversion of roles needs to take place. If this doesn’t happen the master system risks to overwrite the new data in the slave system with the old data it had before the break up. The stopping of the auto update mechanism or the roles inversion must occur automatically in case of master system failure.
A real case
Spazio IT has implemented for the Gruppo Trinità a Disaster Recovery Solution with the following characteristics:
- Master System
- Server Machine – a KVM virtual machine hosted at OVH premises (in Strasbourg, France) with 4GB of RAM and 150GB of hard disk
- Backup Machine – an FTP Area always hosted at OVH premises
- Slave System
- Server Machine – a VMware virtual machine hosted at one of Gruppo Trinità farms (nearby Verona, North-East of Italy) with 4GB of RAM and 150GB of hard disk
- Backup Machine – a small, economic, NAS local to the server machine
- Update Rate – Three times a day (RPO: 8 hours, RTO: 0 hours – immediate)
- Connectivity Master –> Slave – Average 70/80 Mbps – Minimum 15 Mbps